
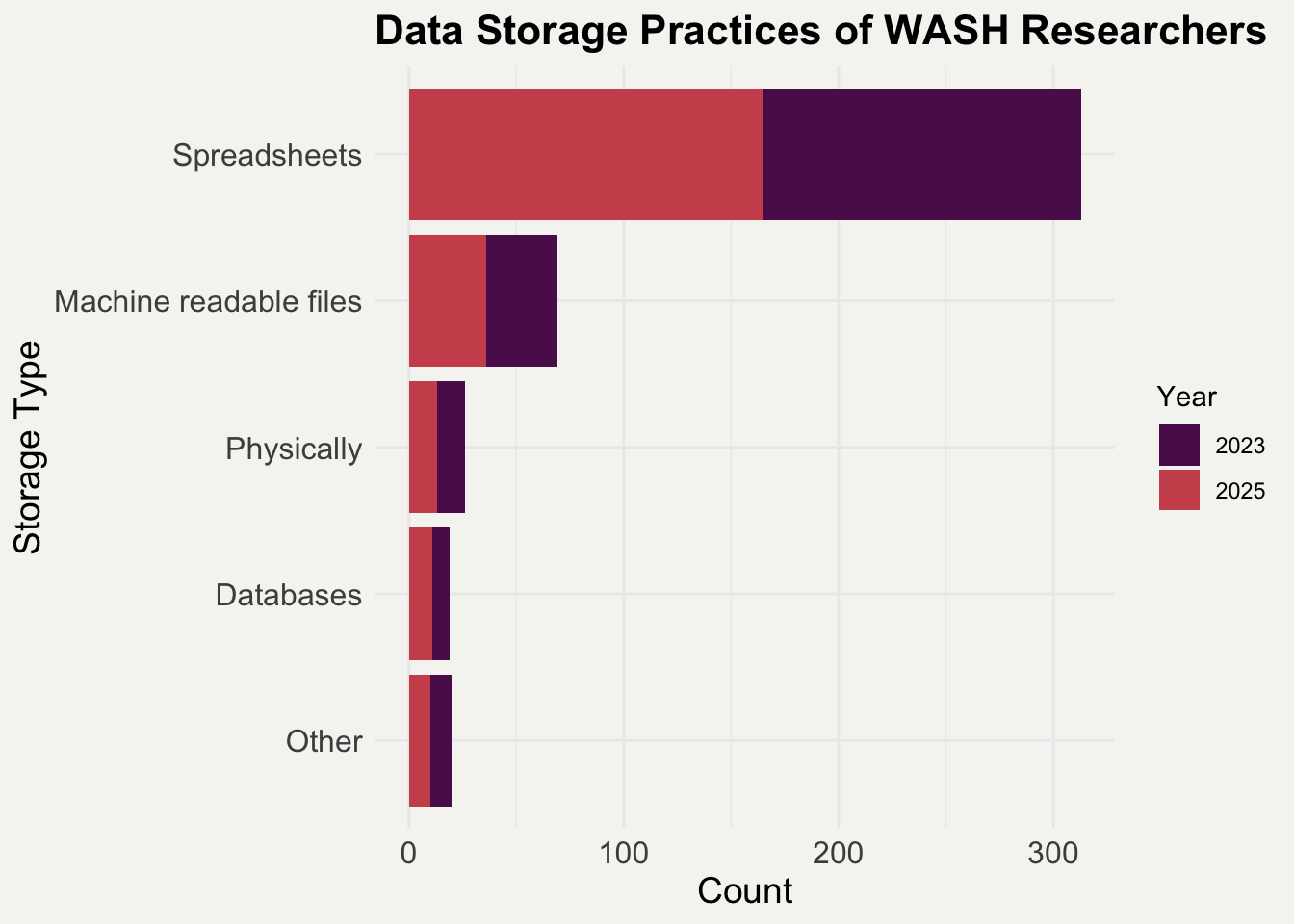
Working with Water, Sanitation, and Hygiene (WASH) researchers across multiple resource-limited countries, we observed that valuable datasets often remain underutilized. This is frequently due to limited familiarity with FAIR (Findable, Accessible, Interoperable, Reusable) data practices (Wilkinson et al. 2016). As part of the academic community, we recognize that research extends beyond traditional metrics like citations and publications. The demanding work of generating, collecting, and cleaning data frequently goes unrecognized, leaving many contributors unacknowledged. As part of GHE’s Open Science project openwashdata we conducted surveys with participants from our network of collaborators who were interested in participating in a Data Science for Open WASH Data course. The collected data reveals suboptimal data storage practices among WASH researchers, with many still relying on methods that hinder portability and interoperability (see Figure 1).
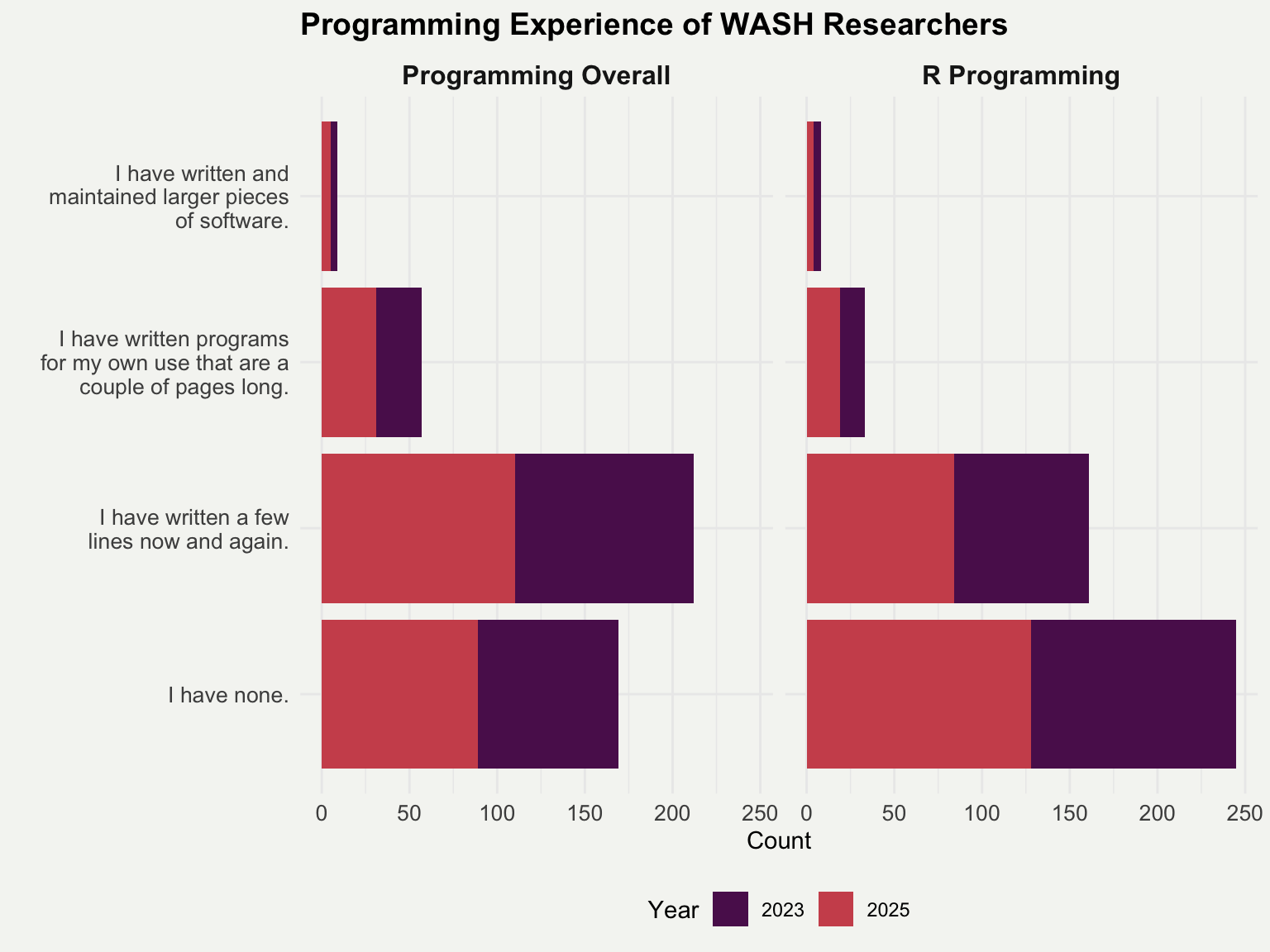
The survey data also shows varying levels of programming proficiency (see Figure Figure 2), with many researchers having limited experience with R specifically. This highlights the need for user-friendly tools that don’t require extensive programming knowledge. A primary barrier is the lack of accessible tools that simplify data publication and distribution using open-source software. This challenge motivated the creation of washr, an R package that streamlines the process of transforming raw data into publication-ready data packages using devtools utilities.
To complement washr, we developed a comprehensive data publishing guide as an online book using R and Quarto. This resource provides step-by-step instructions for creating data packages, including automated website generation where datasets are available for download in CSV and XLSX formats. The guide also covers version control with Git and GitHub, and DOI generation through Zenodo integration.
Following user feedback and recognizing the broader academic community’s need for accessible open data tools, we developed fairenough: an enhanced R package designed for more efficient data publishing workflows with minimal user input requirements. It provides a complete pipeline for R data package creation with the following features:
- One-command pipeline: Complete R data package creation with a single command featuring an automated and interactive workflow from tidy data to finished package and website.
- Granular control options: Individual wrapper functions with the alternative for overwriting documentation and optional detailed messages of the process in the console.
Compared with washr this new iteration minimizes the input required from users by reusing all the information provided when possible and suggesting content. For instance, fairenough leverages LLMs through ellmer to automatically generate data dictionaries. We also plan to provide a detailed guide for working with fairenough.
By automating metadata generation, ensuring proper documentation, enabling version control, and facilitating DOI assignment through Zenodo, fairenough directly addresses each component of the FAIR principles—making data Findable through comprehensive metadata, Accessible via the R data package and download options in the website, Interoperable by providing data and metadata in machine-readable formats, and Reusable with clear licensing and attribution.
We were thrilled to have the opportunity to present fairenough to the public last December at the LatinR conference and received positive encouraging comments about this project. Our proposal was accepted as a lightning talk where we could demonstrate how to create an R data package and a website in a few minutes! We were lucky to share the (virtual) stage with other R enthusiasts who also presented interesting new tools. Discovering existing efforts for open science and reproducibility coming from different perspectives also enriches the development process of fairenough. It was especially motivating to participate in a space where we can reach and get feedback from Spanish and Portuguese speaking communities. We firmly believe that the lack of knowledge of open data and open science practices poses a significant barrier for their adoption and that’s why reaching a larger and more diverse audience has also become part of our mission.
Resources:
- Learn how to get and get started with fairenough: https://openwashdata.github.io/fairenough/
- Slides of our lightning talk at LatinR: https://openwashdata.org/pages/gallery/slides/#introducing-fairenough-at-latinr-2025
- LatinR YouTube channel: https://www.youtube.com/latinr
Note: This post was originally published in GHE’s blog (https://ghe.ethz.ch/ghe-blog-news/2026/02/blog-simplifying-research-data-sharing-with-r.html)